NeerMatch
Neural Networks for Entity Matching in Economic History
The project is funded by DFG as part of the Infrastructure Priority Program New Data Spaces for the Social Sciences (SPP2431) under Grant 539465691.
16th Swedish Economic History Conference in Umeå, 2025-10-09
Motivation
| (index) | Model (alphanumeric) | Producer (alphanumeric) | Origin (alphanumeric) | Sales (in Mil.) (numeric) |
|---|---|---|---|---|
| 1 | Model T | Ford | USA | 16.5 |
| 2 | Model A | Ford | USA | 4.8 |
| 3 | Beetle | Volkswagen | Germany | 21.5 |
| (index) | Name (alphanumeric) | Firm (alphanumeric) | Country (alphanumeric) | Engine (in Lt.) (numeric) |
|---|---|---|---|---|
| 1 | T Model | Ford | United States | 2.9 |
| 2 | Corolla | Toyota | Japan | 1.8 |
| 3 | Beetle | Volkswagen | Germany | 1.6 |
| 4 | Mdl 124 | Fiat | Italy | 1.4 |
A record matching toy example with two sources.
| (index) | Model (alphanumeric) | Producer (alphanumeric) | Origin (alphanumeric) | Sales (in Mil.) (numeric) |
|---|---|---|---|---|
| 1 | Model T | Ford | USA | 16.5 |
| 2 | Model A | Ford | USA | 4.8 |
| 3 | Beetle | Volkswagen | Germany | 21.5 |
| (index) | Name (alphanumeric) | Firm (alphanumeric) | Country (alphanumeric) | Engine (in Lt.) (numeric) |
|---|---|---|---|---|
| 1 | T Model | Ford | United States | 2.9 |
| 2 | Corolla | Toyota | Japan | 1.8 |
| 3 | Beetle | Volkswagen | Germany | 1.6 |
| 4 | Mdl 124 | Fiat | Italy | 1.4 |
(Levenshtein 1965 similarity) (Model T, Mdl 124) = 0.8
(Hamming 1950 similarity) (Model T, Mdl 124) = 0.75
| (index) | Model (alphanumeric) | Producer (alphanumeric) | Origin (alphanumeric) | Sales (in Mil.) (numeric) |
|---|---|---|---|---|
| 1 | Model T | Ford | USA | 16.5 |
| 2 | Model A | Ford | USA | 4.8 |
| 3 | Beetle | Volkswagen | Germany | 21.5 |
| (index) | Name (alphanumeric) | Firm (alphanumeric) | Country (alphanumeric) | Engine (in Lt.) (numeric) |
|---|---|---|---|---|
| 1 | T Model | Ford | United States | 2.9 |
| 2 | Corolla | Toyota | Japan | 1.8 |
| 3 | Beetle | Volkswagen | Germany | 1.6 |
| 4 | Mdl 124 | Fiat | Italy | 1.4 |
(Levenshtein 1965 similarity) (Model T, T Model) = 0.75
(Token sort ratio) (Model T, T Model) = 1
Previous Work
- (Helgertz et al. 2022; Feigenbaum 2016; Price et al. 2021; Abramitzky et al. 2021; Feigenbaum et al. 2025; Stringham 2022;) Census Data Entity Matching.
- (Li et al. 2021; Doll et al. 2021; Mudgal et al. 2018; Ebraheem et al. 2018; Ding et al. 2024; Low et al 2024; Huang et al. 2022; Yao et al. 2022) State-of-the-art end-to-end record matching systems.
Contribution
- Introduces ANNs for entity matching in Economic History.
- Allows the user to chose various similarity metrics/concepts for multiple variable pairs.
- 22 pre-defined similarity concepts.
- Multiple data types.
- Possibility to use custom similarity metrics.
- Missing values do not impose a challenge.
- Network learns optimal weights of variable pairs and associated similarity metrics.
- Works with dirty data & all kinds of entities (e.g., persons, companies, geographic areas)
- Parallelization reduces need for blocking.
Methodology
Similarity Encoding Data Transformation
Network Architecture
Network Architecture
Network Architecture
Network Architecture
Network Architecture
Network Architecture
Network Architecture
Applications
Matching Historical Company Entities
| (1) Iteration | (2) TP | (3) FP | (4) TN | (5) FN | (6) Accuracy | (7) Precision | (8) Recall | (9) F-Score |
|---|---|---|---|---|---|---|---|---|
| 1 | 256 | 0 | 6430 | 2 | 99.97 | 100 | 99.22 | 99.61 |
| 2 | 253 | 0 | 6430 | 5 | 99.93 | 100 | 98.06 | 99.02 |
| 3 | 256 | 2 | 6428 | 2 | 99.94 | 99.22 | 99.22 | 99.22 |
| 4 | 257 | 0 | 6430 | 1 | 99.99 | 100 | 99.61 | 99.81 |
| 5 | 258 | 4 | 6426 | 0 | 99.94 | 98.47 | 100 | 99.23 |
| Average | 256 | 1.2 | 6428.8 | 2 | 99.95 | 99.53 | 99.22 | 99.38 |
Matching Historical Natural Person Entities
| (1) Iteration | (2) TP | (3) FP | (4) TN | (5) FN | (6) Accuracy | (7) Precision | (8) Recall | (9) F-Score |
|---|---|---|---|---|---|---|---|---|
| 1 | 54 | 0 | 266 | 0 | 100 | 100 | 100 | 100 |
| 2 | 54 | 0 | 266 | 0 | 100 | 100 | 100 | 100 |
| 3 | 54 | 0 | 266 | 0 | 100 | 100 | 100 | 100 |
| 4 | 54 | 0 | 266 | 0 | 100 | 100 | 100 | 100 |
| 5 | 54 | 0 | 266 | 0 | 100 | 100 | 100 | 100 |
| Average | 54 | 0 | 266 | 0 | 100 | 100 | 100 | 100 |
Usage & Documentation
Packages
Python Interface
similarity_map = {
"company_name": [
"levenshtein",
"partial",
my_custom_awesome_similarity
],
"address~address1": [ "partial" ],
"address~address2": [ "partial" ],
"purpose": [
"sort",
lambda x, y: x*y + 0.42 - y*x
],
"foundation": [
"discrete",
"partial"
]
}
model = match.MatchingModel(similarity_map)
model.compile(
loss="binary_crossentropy",
optimizer=tensorflow.keras.optimizers.Adam(learning_rate=0.01),
metrics=evaluation_metrics)
train_left, train_right, train_matches = load_train_data()
model.fit(train_left, train_right, train_matches, epochs=100)
model.evaluate(train_left, train_right, train_matches)
predictions = model.predict(train_left, train_right)
suggestions = model.suggest(train_left, train_right, 3)R Interface
similarity_map <- list(
company_name = c(
"levenshtein",
"partial",
my_custom_awesome_similarity
),
`address~address1` = c("partial"),
`address~address2` = c("partial"),
purpose = c(
"sort",
function(x, y) x*y + 0.42 - y*x
),
foundation = c(
"discrete",
"partial"
)
)
model <- matching_model(similarity_map)
model |> compile(
loss = keras::loss_binary_crossentropy(),
optimizer = keras::optimizer_adam(learning_rate = 1e-3),
metrics = evaluation_metrics)
train_left, train_right, train_matches <- load_train_data()
model |> fit(left_train, right_train, matches_train, epochs = 100L)
model |> evaluate(left_test, right_test, matches_test)
predictions <- model |> predict(left, right)
suggestions <- model |> suggest(left, right, count = 3)Remaining Challenges
Increasing Training Data
More training data generally improves matching performance.
- However, due to the quadratic nature of the matching problem, the model learns to predict all record pairs as non-matches.
- F1 loss function
- Focal loss function
- Combined loss function
Overspecification of the model
You can choose as many variable pairs and similarity metrics as you like.
- However, if the network becomes too wide, backpropagation can get stuck in local minima instead of reaching the global minimum.
- This can degrade matching performance.
- Avoid highly correlated metrics.
- Prefer deeper networks over wider ones.
References
Abramitzky, Ran, Leah Boustan, Katherine Eriksson, James Feigenbaum, and Santiago Pérez. (2021). “Automated Linking of Historical Data.” Journal of Economic Literature 59(3): 865–918. https://doi.org/10.1257/jel.20201599
Ding, H., C. Dai, Y. Wu, W. Ma, H.Zhou (2024). “Setem: Self-ensemble training with pre-trained language models for entity matching.” Knowledge-Based Systems 293: 111708. https://doi.org/10.1016/j.knosys.2024.111708
Doll, Hendrik, Eniko Gabor-Toth, and Christopher-Johannes Schild. 2021. “Linking Deutsche Bundesbank Company Data.” Deutsche Bundesbank, Research Data and Service Centre.
Ebraheem, Muhammad, Saravanan Thirumuruganathan, Shafiq Joty, Mourad Ouzzani, and Nan Tang. 2018. “Distributed Representations of Tuples for Entity Resolution.” Proceedings of the VLDB Endowment 11 (11): 1454–67. https://doi.org/10.14778/3236187.3236198.
Feigenbaum, James J. (2016). “A Machine Learning Approach to Census Record Linking.” Working Paper. https://jamesfeigenbaum.github.io/research/pdf/census-link-ml.pdf
Feigenbaum, James J., Jonas Helgertz, and Joseph Price. (2025). “Examining the role of training data for supervised methods of automated record linkage: Lessons for best practice in economic history”. Explorations in Economic History 96: 101656. https://doi.org/10.1016/j.eeh.2025.101656.
Helgertz, Jonas, Joseph Price, Jacob Wellington, Kelly J. Thompson, Steven Ruggles, and Catherine A. Fitch. (2022). “A New Strategy for Linking U.S. Historical Censuses: A Case Study for the IPUMS Multigenerational Longitudinal Panel.” Historical Methods: A Journal of Quantitative and Interdisciplinary History 55(1): 12–29.
https://doi.org/10.1080/01615440.2021.1985027
Hamming, Richard W. 1950. “Error Detecting and Error Correcting Codes.” The Bell System Technical Journal 29 (2): 147–60. https://doi.org/10.1002/j.1538-7305.1950.tb00463.x.
Huang, J., W. Hu, Z. Bao, Q. Chen, and Y. Qu. (2022). “Deep entity matching with adversarial active learning.” The VLDB Journal 32(1): 229–255. https://link.springer.com/article/10.1007/s00778-022-00745-1
Jin, Di, Bunyamin Sisman, Hao Wei, Xin Luna Dong, and Danai Koutra. 2021. “Deep Transfer Learning for Multi-Source Entity Linkage via Domain Adaptation.” In Proceedings of the VLDB Endowment, 15:465–77. https://doi.org/10.14778/3494124.3494131.
Price, Joseph, Kasey Buckles, Jacob Van Leeuwen, and Isaac Riley. (2021). “Combining Family History and Machine Learning to Link Historical Records: The Census Tree Data Set.” Explorations in Economic History 80: 101391. https://doi.org/10.1016/j.eeh.2021.101391
Levenshtein, Vladimir Iosifovich. 1965. “Binary Codes Capable of Correcting Deletions, Insertions, and Reversals.” In Proceedings of the USSR Academy of Sciences, 163:845–48. Russian Academy of Sciences.
Li, Peng, Xiang Cheng, Xu Chu, Yeye He, and Surajit Chaudhuri. 2021. “Auto-FuzzyJoin: Auto-Program Fuzzy Similarity Joins Without Labeled Examples.” In Proceedings of the 2021 International Conference on Management of Data, 1064–76. https://doi.org/10.1145/3448016.3452824.
Low, J. F., B. C. Fung, and P. Xiong. (2024). “Better entity matching with transformers through ensembles.” Knowledge-Based Systems 293: 111678. https://doi.org/10.1016/j.knosys.2024.111678
Mudgal, Sidharth, Han Li, Theodoros Rekatsinas, AnHai Doan, Youngchoon Park, Ganesh Krishnan, Rohit Deep, Esteban Arcaute, and Vijay Raghavendra. 2018. “Deep Learning for Entity Matching: A Design Space Exploration.” In Proceedings of the 2018 International Conference on Management of Data, 19–34. https://doi.org/10.1145/3183713.3196926.
Sadinle, Mauricio. 2017. “Bayesian Estimation of Bipartite Matchings for Record Linkage.” Journal of the American Statistical Association 112 (518): 600–612. https://doi.org/10.1080/01621459.2016.1148612.
Singh, Rohit, Venkata Vamsikrishna Meduri, Ahmed Elmagarmid, Samuel Madden, Paolo Papotti, Jorge-Arnulfo Quiané-Ruiz, Armando Solar-Lezama, and Nan Tang. 2017. “Synthesizing Entity Matching Rules by Examples.” Proceedings of the VLDB Endowment 11 (2): 189–202. https://doi.org/10.14778/3149193.3149199.
Stringham, Thomas. 2022. “Fast Bayesian Record Linkage With Record-Specific Disagreement Parameters.” Journal of Business & Economic Statistics 40 (4): 1509–22. https://doi.org/10.1080/07350015.2021.1934478.
Universitätsbibliothek Mannheim. 2019a. “Handbuch Der Deutschen Aktiengesellschaften.” Heppenheim (Bergstr.), Berlin: urn:nbn:de:bsz:180-dighop-181; Hoppenstedt. http://digi.bib.uni-mannheim.de/urn/urn:nbn:de:bsz:180-dighop-181.
———. 2019b. “Wer Leitet.” Heppenheim (Bergstr.), Berlin: urn:nbn:de:bsz:180-dighop-43; Hoppenstedt. http://digi.bib.uni-mannheim.de/urn/urn:nbn:de:bsz:180-dighop-43.
Wang, Zhengyang, Bunyamin Sisman, Hao Wei, Xin Luna Dong, and Shuiwang Ji. 2020. “CorDEL: A Contrastive Deep Learning Approach for Entity Linkage.” In 2020 IEEE International Conference on Data Mining (ICDM), 1322–27. IEEE. https://doi.org/10.1109/ICDM50108.2020.00171.
Wu, Renzhi, Sanya Chaba, Saurabh Sawlani, Xu Chu, and Saravanan Thirumuruganathan. 2020. “Zeroer: Entity Resolution Using Zero Labeled Examples.” In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, 1149–64. https://doi.org/10.1145/3318464.3389743.
Yao, D., Y. Gu, G. Cong, G. Jin, and X. Lv (2022). “Entity resolution with hierarchical graph attention networks.” In: Proceedings of the 2022 International Conference on Management of Data, pp. 429–442. https://dl.acm.org/doi/10.1145/3514221.3517872
Appendix: Fields, Similarities, and Ratios used in the Applications
Handbuch der Deutschen Aktiengesellschaften



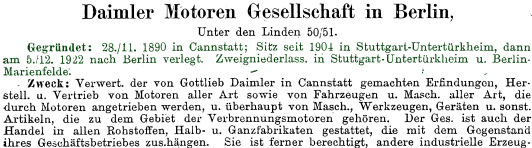






Handbuch der deutschen Aktiengesellschaften (2019a)
| Left Field | Right Field | Similarities | Ratios |
|---|---|---|---|
| company name | company name | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| company info 1 | company info 1 | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| company info 2 | company info 2 | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| found date | found date | discrete | |
| found year | found year | discrete | |
| register date | register date | discrete | |
| register year | register year | discrete | |
| concession date | concession date | discrete | |
| concession year | concession year | discrete | |
| statue change date | statue change date | discrete | |
| company name | company info 1 | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| company name | company info 2 | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| company info 1 | company info 2 | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
Wer Leitet (2019b)
| Left Field | Right Field | Similarities | Ratios |
|---|---|---|---|
| main info | main info | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| Vorstand | Vorstand | Levenshtein, Jaro-Winkel | |
| StVdAR | StVdAR | Levenshtein, Jaro-Winkel | |
| GeschF | GeschF | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| Leiter | Leiter | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| Beirat | Beirat | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| AR | AR | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| name | name | Levenshtein, Jaro-Winkel, discrete | |
| surname | surname | Levenshtein, Jaro-Winkel, discrete | |
| occupation | occupation | Levenshtein, Jaro-Winkel, discrete | |
| address | address | Levenshtein, Jaro-Winkel | partial, token sort, token set, partial token set |
| birth date | birth date | discrete | |
| raw text | raw text | token set, partial token set |